12 самых быстрых суперкомпьютеров в мире — в 2020 году
Содержание:
- Tianhe-2 / Млечный путь-2
- Основные модификации
- Измерение производительности
- Распределенные суперкомпьютеры
- Дальнейшее развитие
- Береговые ракетные комплексы «Редут»
- Варианты
- Российские суперкомпьютеры
- Дробаш с 8-ю стволами – сумасшествие американских оружейников или реально эффективное оружие
- Ссылки
- Характеристики Christofari
- Численность
- Производительность
- Применение
- Конструкция боевой единицы
- Stampede – PowerEdge C8220
- Внешние ссылки и литература
- K Computer
- Для чего используются суперкомпьютеры?
- Представление
Tianhe-2 / Млечный путь-2
- Местоположение: Китай
- Производительность: 33,86 петафлопс
- Теоретический максимум производительности: 54,9 петафлопс
- Мощность: 17,6 МВт
С момента своего первого запуска «Тяньхэ-2», или «Млечный-путь-2», вот уже около двух лет является лидером Top-500. Этот монстр почти в два раза превосходит по производительности №2 в рейтинге – суперкомпьютер TITAN.
Разработанный Оборонным научно-техническим университетом Народно-освободительной армии КНР и компанией Inspur, «Тяньхэ-2» состоит из 16 тысяч узлов с общим количеством ядер в 3,12 миллиона. Оперативная память всей это колоссальной конструкции, занимающей 720 квадратных метров, составляет 1,4 петабайт, а запоминающего устройства – 12,4 петабайт.
«Млечный путь-2» был сконструирован по инициативе китайского правительства, поэтому нет ничего удивительного в том, что его беспрецедентная мощь служит, судя по всему, нуждам государства. Официально было заявлено, что суперкомпьютер занимается различными моделированиями, анализом огромного количества данных, а также обеспечением государственной безопасности Китая.
Учитывая секретность, свойственную военным проектам КНР, остается лишь догадываться, какое именно применение время от времени получает «Млечный путь-2» в руках китайской армии.
Суперкомпьютер Tianhe-2
Основные модификации
-
- Т-72АК — командирский танк с уменьшенным боекомплектом и дополнительными средствами связи.
- Т-72М — экспортный вариант танка Т-72А 1980 года. Он отличался броневой конструкцией башни, комплектацией боеприпасов и системой коллективной защиты.
Т-72АВ — версия 1985 года с навесной динамической защитой.
Измерение производительности
Возможности против емкости
Суперкомпьютеры обычно стремятся к максимальным вычислительным возможностям, а не к вычислительным мощностям. Вычисление возможностей обычно понимается как использование максимальной вычислительной мощности для решения одной большой проблемы в кратчайшие сроки. Часто система возможностей способна решить проблему такого размера или сложности, которую не может сделать ни один другой компьютер, например, очень сложное приложение для моделирования погоды .
Вычисление емкости, напротив, обычно рассматривается как использование эффективной рентабельной вычислительной мощности для решения нескольких довольно больших проблем или множества мелких проблем. Архитектуры, которые позволяют поддерживать множество пользователей для выполнения рутинных повседневных задач, могут обладать большой емкостью, но обычно не считаются суперкомпьютерами, поскольку они не решают ни одной очень сложной проблемы.
Показатели эффективности
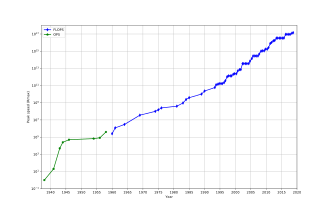
Максимальная скорость суперкомпьютера: скорость в логарифмическом масштабе за 60 лет
Обычно скорость суперкомпьютеров измеряется и оценивается в FLOPS («операции с плавающей запятой в секунду»), а не в MIPS («миллион инструкций в секунду»), как в случае с компьютерами общего назначения. Эти измерения обычно используются с префиксом SI, таким как tera- , в сочетании с сокращением «TFLOPS» (10 12 FLOPS, произносится как терафлопс ) или пета- , объединенным в сокращение «PFLOPS» (10 15 FLOPS, произносится как петафлопс .) « Petascale» «суперкомпьютеры могут обрабатывать один квадриллион (10 15 ) (1000 триллионов) FLOPS. Exascale — это производительность вычислений в диапазоне exaFLOPS (EFLOPS). EFLOPS — это один квинтиллион (10 18 ) FLOPS (один миллион TFLOPS).
Ни одно число не может отражать общую производительность компьютерной системы, но цель теста Linpack — приблизительно оценить, насколько быстро компьютер решает числовые задачи, и он широко используется в отрасли. Измерение FLOPS основано либо на теоретической производительности процессора с плавающей запятой (полученной из спецификаций процессора производителя и показанной как «Rpeak» в списках TOP500), что обычно недостижимо при выполнении реальных рабочих нагрузок, либо на достижимой пропускной способности, полученной из в Linpack тесты и показали , как «Rmax» в списке TOP500. Тест LINPACK обычно выполняет LU-разложение большой матрицы. Производительность LINPACK дает некоторое представление о производительности для некоторых реальных проблем, но не обязательно соответствует требованиям обработки многих других рабочих нагрузок суперкомпьютеров, которые, например, могут потребовать большей пропускной способности памяти, или могут потребовать лучшей производительности целочисленных вычислений, или могут потребоваться высокопроизводительная система ввода-вывода для достижения высокого уровня производительности.
Список ТОП500

20 лучших суперкомпьютеров мира (июнь 2014 г.)
С 1993 года самые быстрые суперкомпьютеры попадают в список TOP500 в соответствии с результатами тестов LINPACK . Список не претендует на беспристрастность или окончательность, но это широко цитируемое текущее определение «самого быстрого» суперкомпьютера, доступного в любой момент времени.
Это недавний список компьютеров, которые оказались в верхней части списка TOP500, а «Пиковая скорость» дана как рейтинг «Rmax». В 2018 году Lenovo стала крупнейшим в мире поставщиком суперкомпьютеров TOP500, выпустив 117 единиц.
| Год | Суперкомпьютер | Rmax (TFlop / s) | Место расположения |
|---|---|---|---|
| 2020 г. | Fujitsu Fugaku | 442 010,0 | Кобе , Япония |
| 2018 г. | Саммит IBM | 148 600,0 | Ок-Ридж , США |
| 2018 г. | IBM / Nvidia / Mellanox Sierra | 94 640,0 | Ливермор , США |
| 2016 г. | Sunway TaihuLight | 93 014,6 | Уси , Китай |
| 2013 | НУДТ Тяньхэ-2 | 61 444,5 | Гуанчжоу , Китай |
| 2019 г. | Dell Frontera | 23 516,4 | Остин , США |
| 2012 г. | Крей / HPE Piz Daint | 21 230,0 | Лугано , Швейцария |
| 2015 г. | Cray / HPE Trinity | 20 158,7 | Нью-Мексико , США |
| 2018 г. | Fujitsu ABCI | 19 880,0 | Токио , Япония |
| 2018 г. | Lenovo SuperMUC-NG | 19 476,6 | Гархинг , Германия |
Распределенные суперкомпьютеры
Оппортунистические подходы
Пример архитектуры системы грид-вычислений , соединяющей множество персональных компьютеров через Интернет.
Оппортунистический суперкомпьютер — это форма сетевых грид-вычислений, при которой «супер-виртуальный компьютер» из множества слабосвязанных вычислительных машин-добровольцев выполняет очень большие вычислительные задачи. Грид-вычисления применялись к ряду крупномасштабных до неловко параллельных задач, требующих масштабирования производительности суперкомпьютеров. Однако базовые подходы к сетевым и облачным вычислениям , основанные на добровольных вычислениях, не могут справиться с традиционными задачами суперкомпьютеров, такими как гидродинамическое моделирование.
Самая быстрая система распределенных вычислений — это проект распределенных вычислений Folding @ home (F @ h). По состоянию на апрель 2020 года компания F @ h сообщила о 2,5 эксафлопс вычислительной мощности x86 . Из них более 100 пфлопс приходится на клиентов, работающих на различных графических процессорах, а остальные — на различные системы ЦП.
Платформа Berkeley Open Infrastructure for Network Computing (BOINC) содержит ряд проектов распределенных вычислений. По состоянию на февраль 2017 года BOINC зафиксировал вычислительную мощность более 166 петафлопс на более чем 762 тысячах активных компьютеров (хостов) в сети.
Квази-оппортунистические подходы
Квазиоппортунистические суперкомпьютеры — это форма распределенных вычислений, при которой «супервиртуальный компьютер» многих сетевых географически разнесенных компьютеров выполняет вычислительные задачи, требующие огромной вычислительной мощности. Квази-оппортунистические суперкомпьютеры нацелены на обеспечение более высокого качества обслуживания, чем гибкие грид-вычисления, за счет достижения большего контроля над назначением задач распределенным ресурсам и использования информации о доступности и надежности отдельных систем в суперкомпьютерной сети. Однако квазиоппортунистическое распределенное выполнение требовательного программного обеспечения для параллельных вычислений в гридах должно достигаться за счет реализации соглашений о распределении по сетке, подсистем совместного размещения, механизмов распределения с учетом топологии связи, отказоустойчивых библиотек передачи сообщений и предварительной обработки данных.
Дальнейшее развитие
Береговые ракетные комплексы «Редут»
Варианты
В состав системы входят:
- Mk 16 Mod 0, SCAR-L (англ. Light — лёгкий) — автомат калибра 5,56 НАТО, предназначенный для замены М4 и M16.
- Mk 17 Mod 0, SCAR-H (англ. Heavy — тяжёлый) — винтовка калибра 7,62 НАТО, предназначенная для замены M14 и M110 (в версии SSR)
- Mk 20 Mod 0, SCAR SSR (англ. Sniper Support Rifle — оружие поддержки снайпера) — «снайперский» вариант 7.62-мм автоматической винтовки SCAR-H Mk 17 Mod 0
- Mk 13 Mod 0 или EGLM — гранатомёт, может использоваться в качестве подствольного для обоих вариантов, а также как самостоятельное оружие (при установке на специальный модуль, имеющий приклад и пистолетную рукоятку).
Оба варианта FN SCAR могут иметь три различных конфигурации, различающиеся длиной ствола:
- CQC (Close Quarters Combat — вариант для ближнего боя)
- STD (Standard — стандартный вариант)
- SV (Sniper Variant — снайперский вариант).
Смена ствола возможна силами самого бойца за несколько минут при использовании минимума инструментов (взаимозаменяемость деталей составляет около 90 %).
Другие варианты
- FN SCAR SSR (англ. Sniper Support Rifle — снайперская винтовка поддержки) — полуавтоматическая снайперская винтовка, в 2010 году принятая на вооружение сил Командования Специальных Операций США (US SOCOM) под индексом Mark 20 (Mk.20 Mod.0). Винтовка может вести одиночный огонь и очередью по два выстрела.
- FNAC (Advanced Carbine — улучшенный карабин) — упрощённый вариант Mk 16 Standard. Основное отличие — отсутствие возможности быстрой смены ствола. Мушка смонтирована на ствольной коробке, тогда как у Мк 16 — в месте примыкания газоотводной трубки к стволу, имеется крепление для штыка (отсутствующее на Мк 16), рукоять заряжания неподвижна во время стрельбы. FNAC также несколько легче Мк 16: 6,9 фунта (3,1 кг) и 7,2 фунта (3,3 кг) соответственно (для обоих вариантов указан вес оружия без патронов). Участвовал в конкурсе армии США на замену карабина М4, однако конкурс был закрыт перед объявлением победителя.
- FN HAMR (Heat Adaptive Modular Rifle — температурно адаптируемая модульная винтовка) — Инновационная разработка компании FN. FN HAMR по умолчанию, как и большинство автоматов, стреляет с закрытого затвора, что способствует точности огня. Если же в процессе стрельбы температура ствола превышает определённый предел, оружие автоматически переходит в режим стрельбы с открытого затвора (как это характерно для большинства пулемётов), что способствует лучшему охлаждению внутреннего пространства ствольной коробки и позволяет вести огонь длинными очередями. Таким образом HAMR сочетает в себе черты как автоматических винтовок, так и ручных пулемётов. Переключение между этими режимами производит специальный блок расположенный под стволом. Калибр 5, 56 мм, стволы длиной 16 дюймов (410 мм) и 18 дюймов (460 мм).
- В 2008 году HAMR участвовала в конкурсе Infantry Automatic Rifle для Морской пехоты США, который был выигран винтовкой HK416 фирмы Хеклер-Кох (принята на вооружение под обозначением M27).
FN SCAR PDW (Personal Defense Weapon — оружие личной обороны) — вариант, предназначенный для вооружения экипажей боевых машин, вертолётов, технических специалистов и тому подобное. Основное отличие от базовых модификаций SCAR — короткий ствол длиной 6,75 дюйма (170 мм) и упрощённый, нерегулируемый, выдвижной плечевой упор. Длина с выдвинутым плечевым упором 24,9 дюйма (630 мм), со сложенным упором — 20,5 дюйма (520 мм), вес без патронов 5,5 фунта (2,5 кг), эффективная дальность стрельбы — 200 м.
FN CSR-20 (Compact Sniper Rifle — компактная снайперская винтовка) — самозарядная снайперская винтовка с длиной ствола 20″ (508 мм) под патрон 7,62×51 мм НАТО.
Российские суперкомпьютеры
В 55 редакции рейтинга Top500, опубликованной в июне 2020 г., российские компьютеры присутствуют, но не попадают не только в первую десятку, но также в первые двадцатку и тридцатку. Лучшая по состоянию на июнь 2020 г. российская система занимает в рейтинге лишь 36 место.
Это суперкомпьютер «Кристофари», созданный Сбербанком, как сообщал CNews, в ноябре 2019 г. на основе готовых вычислительных узлов Nvidia DGX-2 специально для решения задач искусственного интеллекта. В Сбербанке его называют самым мощным в России.
Суперкомпьютер Сбербанка
В основе «Кристофари», названного в честь Николая Кристофари, который стал первым клиентом российских сберкасс в 1842 г., лежат процессоры Xeon Platinum 8168 с 24-ядрами, а также видеоускорители Nvidia Tesla V100. Суперкомпьютер выдает производительность на уровне 6,669 петафлопс.
Всего в новом рейтинге Top500 представлено два российских суперкомпьютера – вторым стал «Ломоносов-2» производства компании «Т-платформы», установленный в МГУ. Машина состоит из 1536 узлов на базе процессора Intel Xeon E5-2697 с 64 ГБ оперативной памяти и ускорителем Nvidia Tesla K40M, а также 160 узлов на Intel Xeon Gold 6126, 96 ГБ памяти и паре ускорителей Nvidia Tesla P100. Производительность «Ломоносова-2» в тесте Linpack составляет 2,478 петафлопс, и он занимает 131 место в списке самых производительных суперкомпьютеров в мире.
В рейтинге Top500 за ноябрь 2019 г. участвовало три российских компьютера. Среди них были «Кристофари», находившийся на тот момент на 29 месте и менее чем за год потерявший восемь строчек, и «Ломоносов-2» – он занимал 107 место против 131 в июне 2020 г. Третьим участником был суперкомпьютер Cray XC40 Росгидромета, строительство которого началось в 2017 г. силами компании «Т-платформы» и интегратора Inline Teсhnologies. Компьютер заработал в конце января 2018 г., и в ноябре 2019 г. он занимал 465 место с производительностью 1,2 петафлопс. В июне 2020 г. он выбыл из рейтинга.
- Короткая ссылка
- Распечатать
Дробаш с 8-ю стволами – сумасшествие американских оружейников или реально эффективное оружие
Ссылки
Характеристики Christofari
Christofari создан специалистами Сбербанка и Sbercloud в партнерстве с американской компанией Nvidia на базе высокопроизводительных узлов Nvidia DGX-2. Заявленная производительность суперкомпьютера в проведенных тестах Linpack достигла 6,7 петафлопс.
Как пандемия изменила подходы к организации рабочего пространства
Интеграция

В Nvidia DGX-2 называют «самым большим в мире GPU». Устройство, представленное в 2018 г., оснащается двумя процессорами Intel Xeon Platinum и способно работать с 16 видеоускорителями Tesla V100 с 32 ГБ памяти HBM2. Общую пропускную способность в 14,4 ТБ/сек обеспечивают технологии межчиповых соединений NVSwitch и NVLink2.
Производительность одного узла DGX-2 может достигать 2 петафлопс, а ее стоимость на момент анонса составляла $399 тыс.
Численность
Производительность
Производительность суперкомпьютеров чаще всего оценивается и выражается в количестве операций над числами с плавающей точкой в секунду (FLOPS). Это связано с тем, что задачи численного моделирования, под которые и создаются суперкомпьютеры, чаще всего требуют вычислений, связанных с вещественными числами, зачастую с высокой степенью точности, а не целыми числами. Поэтому для суперкомпьютеров неприменима мера быстродействия обычных компьютерных систем — количество миллионов операций в секунду (MIPS). При всей своей неоднозначности и приблизительности, оценка во флопсах позволяет легко сравнивать суперкомпьютерные системы друг с другом, опираясь на объективный критерий.
Первые суперкомпьютеры имели производительность порядка 1 кфлопс, то есть 1000 операций с плавающей точкой в секунду. В США компьютер, имевший производительность в 1 миллион флопсов (1 Мфлопс) (), был создан в 1964 году. Известно, что в 1963 году в московском НИИ-37 (позже НИИ ДАР) был разработан компьютер на основе модулярной арифметики с производительностью 2,4 млн оп/с. Это экспериментальный компьютер второго поколения (на дискретных транзисторах) Т340-А (гл. конструктор Д. И. Юдицкий). Однако следует отметить, что прямое сравнение производительности модулярных и традиционных ЭВМ некорректно. Модулярная арифметика оперирует только с целыми числами. Представление вещественных чисел в модулярных ЭВМ возможно только в формате с фиксированной запятой, недостатком которого является существенное ограничение диапазона представления чисел.
Планка в 1 миллиард флопс (1 Гигафлопс) была преодолена суперкомпьютерами NEC SX-2 в 1983 году с результатом 1.3 Гфлопс.
Граница в 1 триллион флопс (1 Тфлопс) была достигнута в 1996 году суперкомпьютером ASCI Red.
Рубеж 1 квадриллион флопс (1 Петафлопс) был взят в 2008 году суперкомпьютером IBM Roadrunner.
В 2010-х годах несколькими странами ведутся работы, нацеленные на создание к 2020 году экзафлопсных компьютеров, способных выполнять 1 квинтиллион операций с плавающей точкой в секунду и потребляющих при этом не более нескольких десятков мегаватт.
Применение
Суперкомпьютеры используются во всех сферах, где для решения задачи применяется численное моделирование; там, где требуется огромный объём сложных вычислений, обработка большого количества данных в реальном времени, или решение задачи может быть найдено простым перебором множества значений множества исходных параметров (см. Метод Монте-Карло).
Совершенствование методов численного моделирования происходило одновременно с совершенствованием вычислительных машин: чем сложнее были задачи, тем выше были требования к создаваемым машинам; чем быстрее были машины, тем сложнее были задачи, которые на них можно было решать. Поначалу суперкомпьютеры применялись почти исключительно для оборонных задач: расчёты по ядерному и термоядерному оружию, ядерным реакторам. Потом, по мере совершенствования математического аппарата численного моделирования, развития знаний в других сферах науки — суперкомпьютеры стали применяться и в «мирных» расчётах, создавая новые научные дисциплины, как то: численный прогноз погоды, вычислительная биология и медицина, вычислительная химия, вычислительная гидродинамика, вычислительная лингвистика и проч., — где достижения информатики сливались с достижениями прикладной науки.
Ниже приведён далеко не полный список областей применения суперкомпьютеров:
-
Математические проблемы:
- Криптография
- Статистика
-
Физика высоких энергий:
- процессы внутри атомного ядра, физика плазмы, анализ данных экспериментов, проведённых на ускорителях
- разработка и совершенствование атомного и термоядерного оружия, управление ядерным арсеналом, моделирование ядерных испытаний
- моделирование жизненного цикла ядерных топливных элементов, проекты ядерных и термоядерных реакторов
-
Наука о Земле:
- прогноз погоды, состояния морей и океанов
- предсказание климатических изменений и их последствий
- исследование процессов, происходящих в земной коре, для предсказания землетрясений и извержений вулканов
- анализ данных геологической разведки для поиска и оценки нефтяных и газовых месторождений, моделирование процесса выработки месторождений
- моделирование растекания рек во время паводка, растекания нефти во время аварий
Вычислительная биология: фолдинг белка, расшифровка ДНК
Вычислительная химия и медицина: изучение строения вещества и природы химической связи как в изолированных молекулах, так и в конденсированном состоянии, поиск и создание новых лекарств
-
Физика:
- газодинамика: турбины электростанций, горение топлива, аэродинамические процессы для создания совершенных форм крыла, фюзеляжей самолетов, ракет, кузовов автомобилей
- гидродинамика: течение жидкостей по трубам, по руслам рек
- материаловедение: создание новых материалов с заданными свойствами, анализ распределения динамических нагрузок в конструкциях, моделирование крэш-тестов при конструировании автомобилей
- в качестве сервера для искусственных нейронных сетей
- создание принципиально новых способов вычисления и обработки информации (Квантовый компьютер, Искусственный интеллект)
Конструкция боевой единицы
Stampede – PowerEdge C8220
- Местоположение: США
- Производительность: 5,16 петафлопс
- Теоретический максимум производительности: 8,52 петафлопс
- Мощность: 4,5 МВт
Находящийся в Техасе Stampede является единственным в первой десятке Top-500 кластером, который был разработан американской компанией Dell. Суперкомпьютер состоит из 160 стоек.
Этот суперкомпьютер является мощнейшим в мире среди тех, которые применяются исключительно в исследовательских целях. Доступ к мощностям Stampede открыт научным группам. Используется кластер в самом широком спектре научных областей – от точнейшей томографии человеческого мозга и предсказания землетрясений до выявления паттернов в музыке и языковых конструкциях.

Суперкомпьютер Stampede
Внешние ссылки и литература
- Абрамов Е. Диверсионные десанты морской пехоты Северного флота в 1941–1944 годах // Диверсанты Второй мировой / ред.-сост. Г. Пернавский. — М.: «Яуза», «Эксмо», 2008. — С. 175–251. — 352 с. — (Военно-исторический сборник). — 5000 экз. — ISBN 978-5-699-31043-2.
- Абрамов Е. П. Подвиг морской пехоты: «Стой насмерть!». — М.: «Яуза», «Эксмо», 2013. — 416 с. — (Сталинский спецназ. Морпехи). — 2500 экз. — ISBN 978-5-699-62623-6.
K Computer
- Местоположение: Япония
- Производительность: 10,51 петафлопс
- Теоретический максимум производительности: 11,28 петафлопс
- Мощность: 12,6 МВт
Разработанный компанией Fujitsu и расположенный в Институте физико-химических исследований в городе Кобе, K Сomputer является единственным японским суперкомпьютером, присутствующим в первой десятке Top-500.
В свое время (июнь 2011) этот кластер занял в рейтинге первую позицию, на один год став самым производительным компьютером в мире. А в ноябре 2011 года K Computer стал первым в истории, которому удалось достичь мощности выше 10 петафлопс.
Суперкомпьютер используется в ряде исследовательских задач. К примеру, для прогнозирования природных бедствий (что актуально для Японии из-за повышенной сейсмической активности региона и высокой уязвимости страны в случае цунами) и компьютерного моделирования в области медицины.
Для чего используются суперкомпьютеры?
Главной ценностью суперкомпьютеров является их постоянно улучшающаяся способность симулировать реальность. Они могут моделировать производственные условия и разрабатывать более совершенные продукты в областях от нефтегазовой промышленности до фармацевтики. Джек Донгарра, один из ведущих экспертов по суперкомпьютерам, сравнивает эту способность с магическим шаром для предсказаний.
«Например, я хочу узнать, что происходит, когда сталкиваются две галактики. Я не могу провести такой эксперимент. Я не могу взять две галактики и столкнуть их. Поэтому я должен построить модель и запустить ее на компьютере. Или другой пример — в прошлом инженеры при проектировании автомобиля заставляли его врезаться в стену, чтобы увидеть, насколько хорошо он выдержит удар. Но это довольно дорого и требует много времени. Сегодня мы просто создаем компьютерную модель машины и заставляем ее врезаться в виртуальную стену», — отметил Донгарра, добавив, что половина пятисот лучших суперкомпьютеров занята в промышленности.
Высокопроизводительные вычисления также важны для оборонного сектора. В частности, сложные симуляции фактически устранили необходимость реальных испытаний оружия, в том числе ядерного.
Исследовательская лаборатория ВВС — один из пяти центров с суперкомпьютерами Министерства обороны США — выделила четыре суперкомпьютера на исследования в области вооружения. Проект был продвинут как способ помочь ученым «быстро реагировать на самые актуальные и сложные проблемы нашей страны, а также реализовать новые возможности разработки оружия при меньших затратах со стороны налогоплательщиков».
Суперкомпьютеры также используются в области искусственного интеллекта. Как рассказал директор Аргоннской национальной лаборатории Пол Кернс, Aurora предназначена для ИИ следующего поколения, который ускорит научные открытия и сделает возможными улучшения в таких областях, как прогнозирование экстремальных погодных явлений, медицина, картирование головного мозга и разработка новых материалов. Aurora поможет человечеству лучше понять Вселенную, «и это только начало», убежден Кернс.
Однако работа с ИИ — лишь небольшой процент того, что делают суперкомпьютеры. 90% расчетов по-прежнему посвящены традиционным задачам: инженерным симуляциям, моделированию погоды и тому подобному. ИИ занимает во всем этом лишь 5-10%, указывает Эндрю Джонс, консультант по высокопроизводительным вычислениям.
Николь Хемсот, соучредитель The Next Platform, считает, что пройдет еще не менее пяти лет, прежде чем в суперкомпьютеры начнут массово внедрять ИИ и глубокое обучение. При этом будут требоваться куда более мощные вычислительные возможности, чем есть сейчас, отмечает она.
Представление
Заявленная начальная производительность Fugaku составила Rmax 416 петафлопс в тесте высокой производительности LINPACK FP64, используемом TOP500 . После обновления числа процессоров в ноябре 2020 года производительность Fugaku увеличилась до Rmax, равного 442 петафлопс.
Fugaku также занял первые места в других рейтингах, тестирующих компьютеры на различных рабочих нагрузках, включая Graph 500 , HPL-AI и HPCG . Ни один из предыдущих суперкомпьютеров никогда не возглавлял сразу все четыре рейтинга.
После обновления оборудования в ноябре 2020 года «Fugaku увеличила свою производительность в новом эталонном тесте HPC-AI со смешанной точностью до 2,0 экзафлопс, превзойдя отметку 1,4 экзафлопса, зафиксированную шесть месяцев назад. Это первые эталонные измерения выше одного экзафлопса для любой точности. на любом типе оборудования «. (рост на 42%). Интересно, что количество ядер Arm A64FX было увеличено только на 4,5%, до 7630848, но измеренная производительность выросла намного больше в этом тесте (и система не использует другие вычислительные возможности, такие как графические процессоры ), и немного больше в TOP500 , или на 6,4%, до 442 петафлопс, что является новым мировым рекордом и настолько сильно увеличивает разрыв до следующего компьютера. Для теста High-Performance Conjugate Gradient (HPCG) он более чем в 5,4 раза быстрее, с 16,0 HPCG-петафлопс, чем система номер два, Summit , которая также занимает второе место в TOP500.
Производительность Fugaku превосходит совокупную производительность следующих 4 суперкомпьютеров в списке топ-500 (почти следующие 5) и на 45% превосходит все остальные компьютеры из топ-10 в тесте HPCG .